Aggregators¶
Aggregators represent different ways to count and output data as it is processed in rare. Aggregation takes in different formats of the matched and extracted expression, and either counts or analyzes the values.
More Examples
More examples of each can be found in examples. For CLI documentation, run rare help
Filter¶
rare help filter
Summary¶
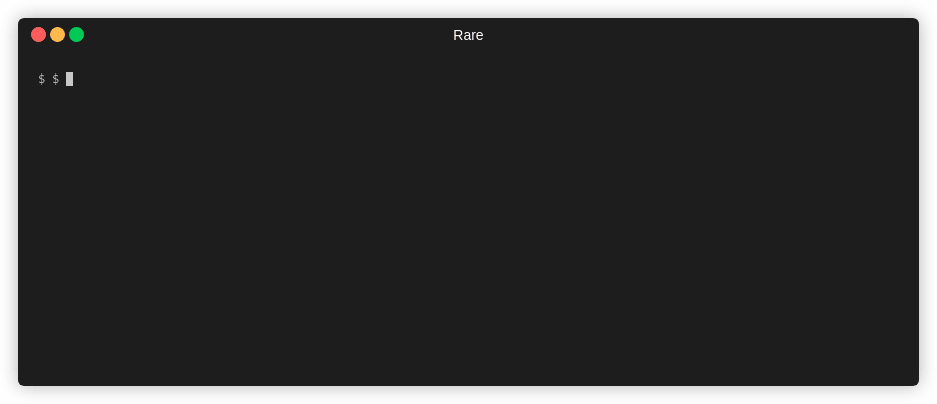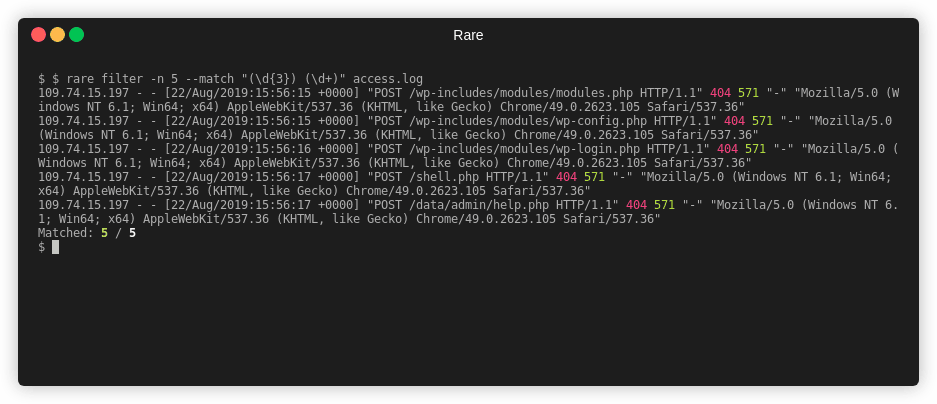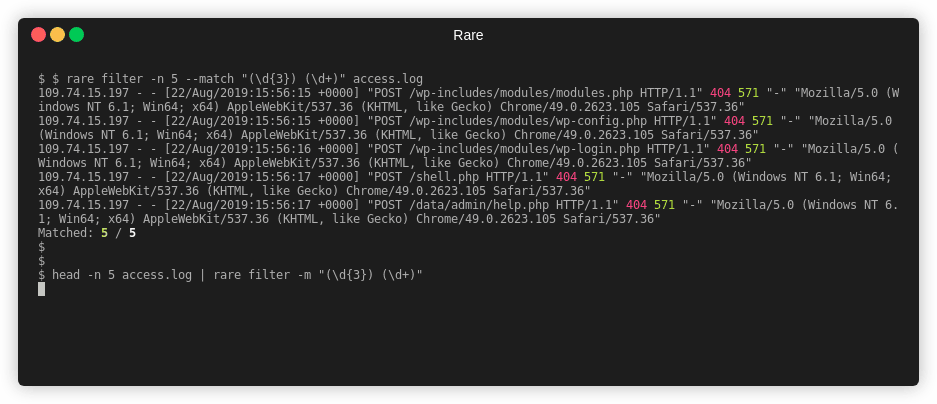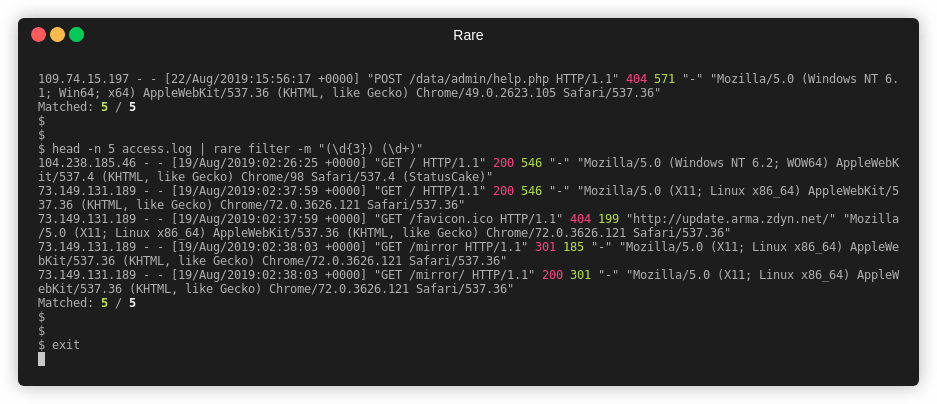
Filter is a command used to match and (optionally) extract that match without
any aggregation. It's effectively a grep or a combination of grep, awk,
and/or sed.
Example¶
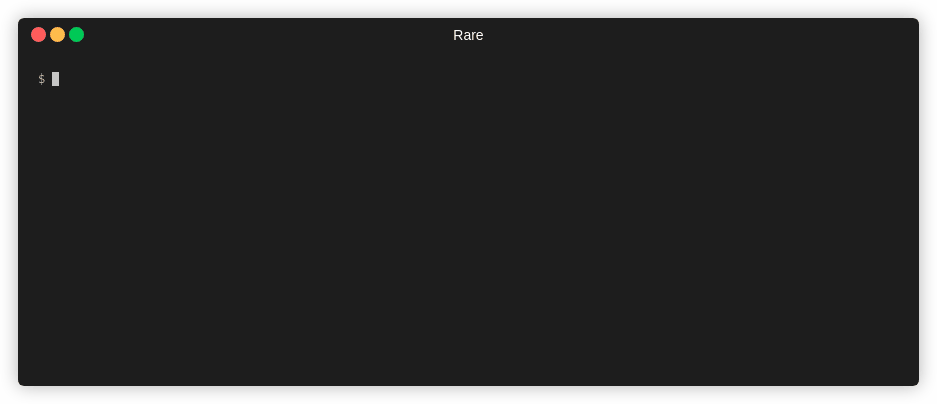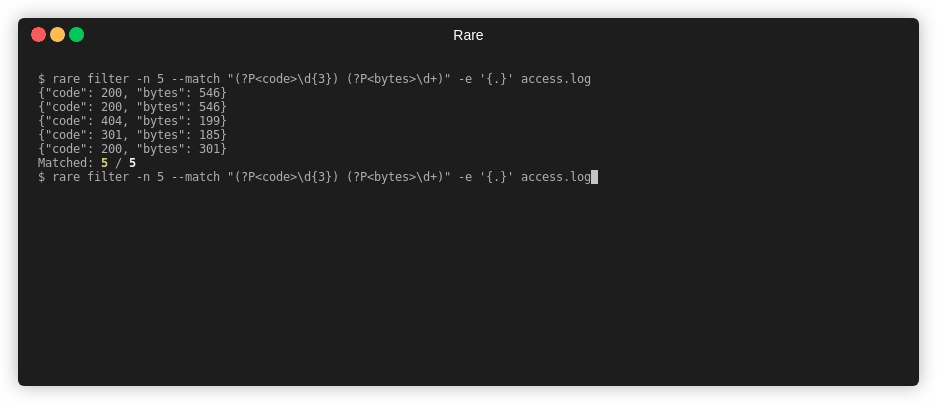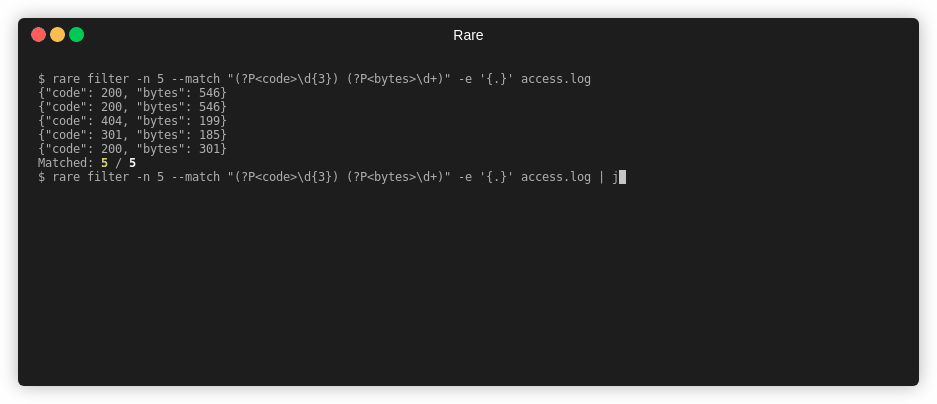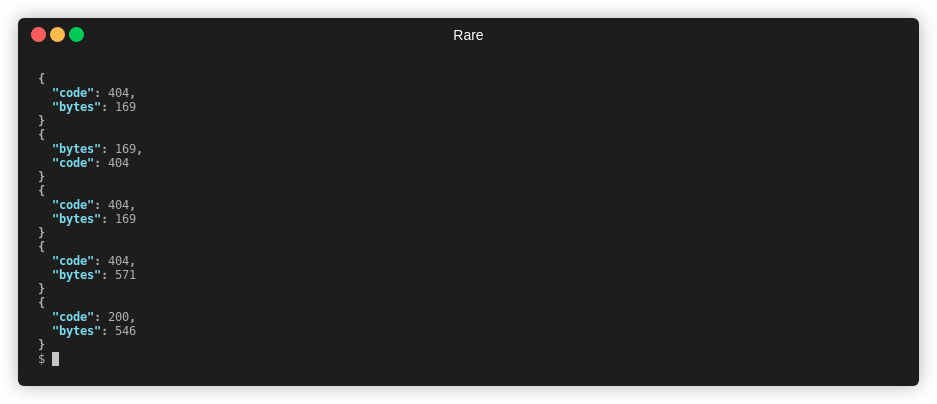
Extract out two numbers from access.log
$ rare filter -n 4 -m "(\d{3}) (\d+)" -e "{1} {2}" access.log
404 169
404 169
404 571
404 571
Matched: 4 / 4
Search¶
rare help search
Summary¶
Search is an alias to filter which changes default settings to make it easier
to find text. It is equivalent to -IRla -m (ignore-case, recursive, line-numbers, text-only).
Unless a matcher is specified explicitly, the first argument will be assumed to be a regex.
If a file path is not provided, it will search the current working directory.
Example¶
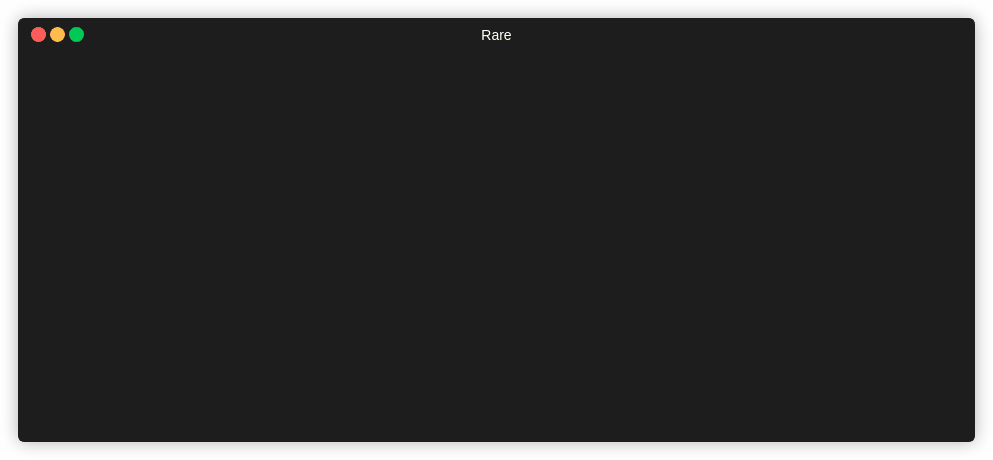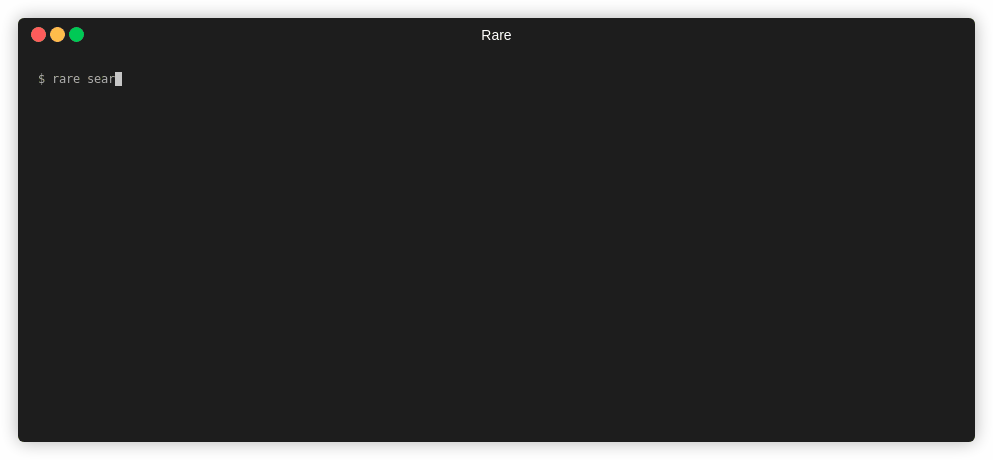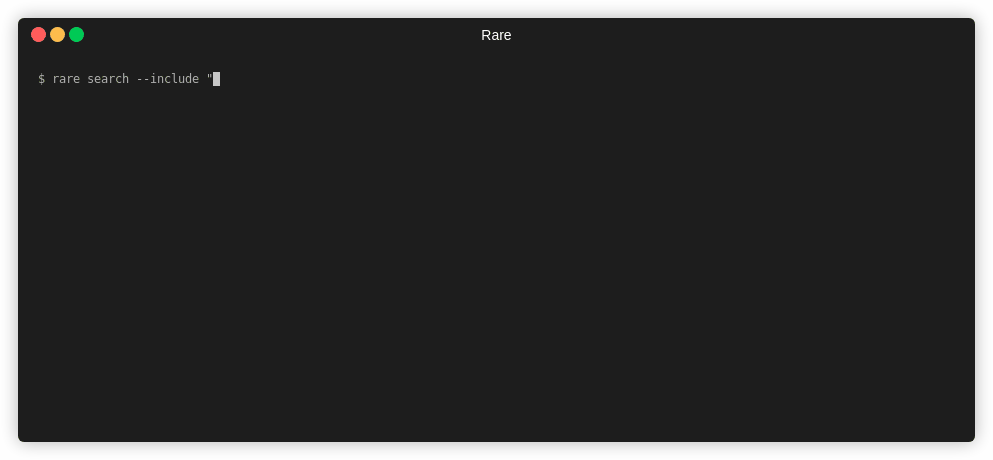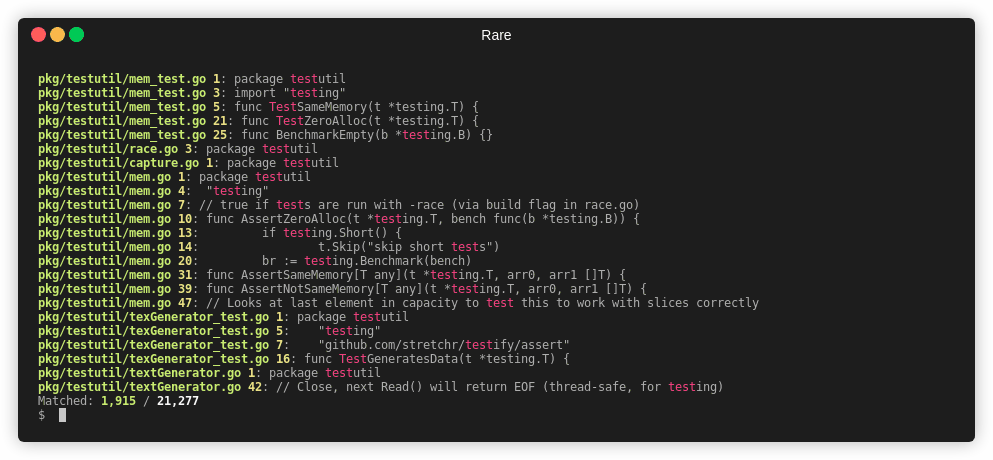
rare search test
# Is equivalent to
rare filter -IRla -m test .
And its output will look like:
access.log 181: x.x.x.x - - [20/Aug/2019:12:09:43 +0000] "GET /test.php HTTP/1.1" 404 571 "-" "Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0)"
access.log 454: x.x.x.x - - [20/Aug/2019:12:11:23 +0000] "POST /test.php HTTP/1.1" 404 571 "-" "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"
Histogram¶
rare help histogram
Summary¶
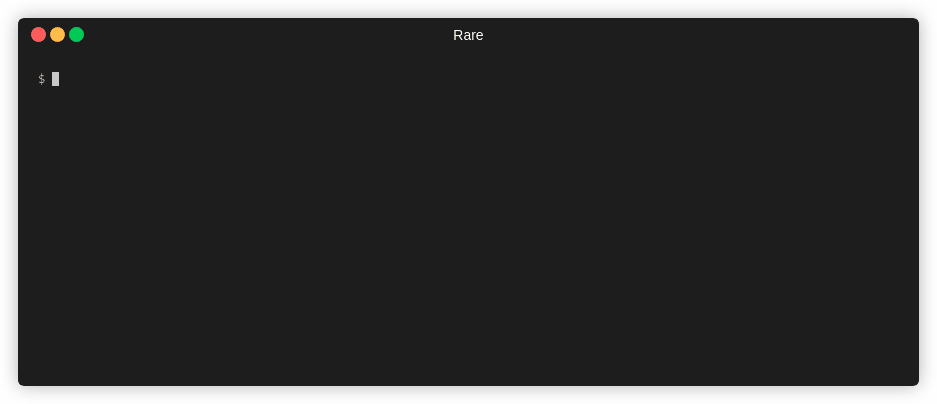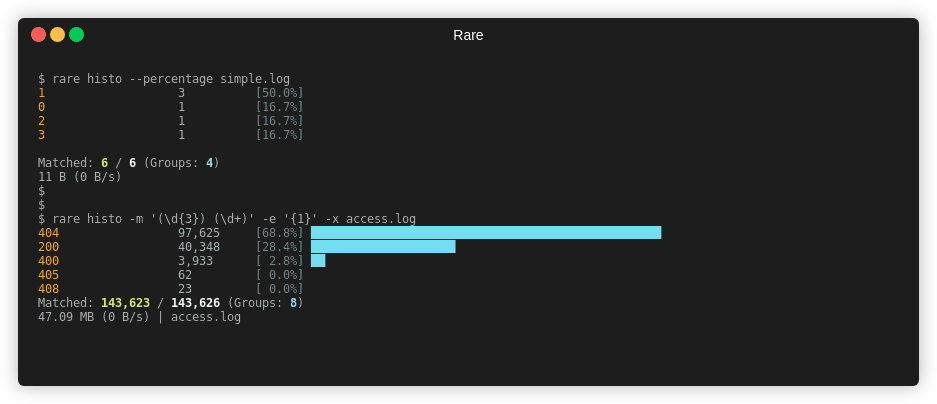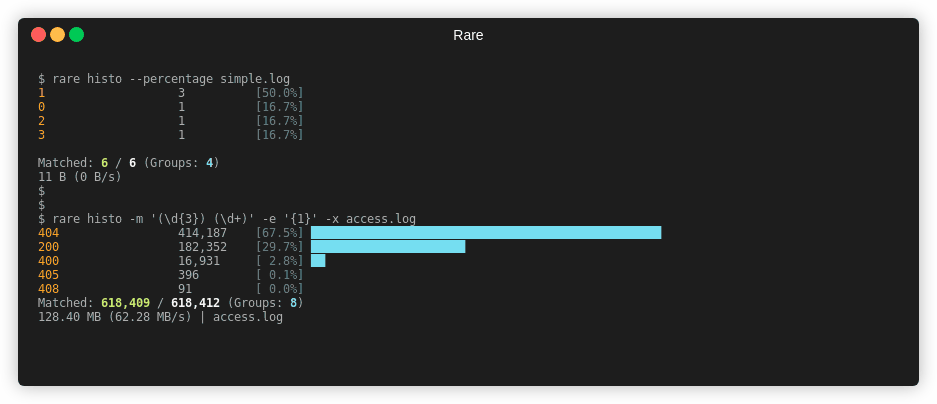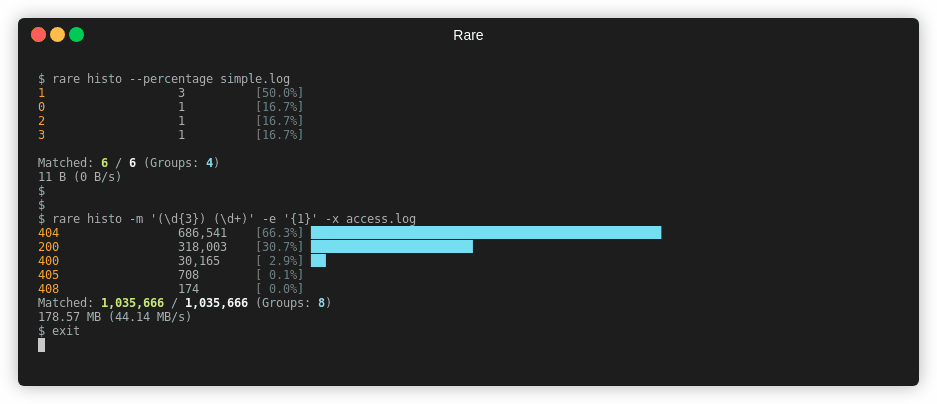
The histogram format outputs an aggregation by counting the occurrences of an extracted match. That is to say, on every line a regex will be matched (or not), and the matched groups can be used to extract and build a key, that will act as the bucketing name.
Supports alternative scales
Example¶
Extract HTTP verb, URL and status code. Key off of status code and verb.
Tip
Use -x to display percentages and a simple bargraph.
$ rare histo -m '"(\w{3,4}) ([A-Za-z0-9/.]+).*" (\d{3})' -e '{3} {1}' access.log
200 GET 160663
404 GET 857
304 GET 53
200 HEAD 18
403 GET 14
Bar Graph¶
rare help bargraph
Summary¶
Similar to histogram or table, bargraph can generate a stacked or grouped bargraph by one or two keys.
Supports alternative scales
Example¶
Color Coded Keys
When run in terminal, below will be color-coded keys. Alternatively, you can leave
off -s (stacking) to see each key displayed vertically.
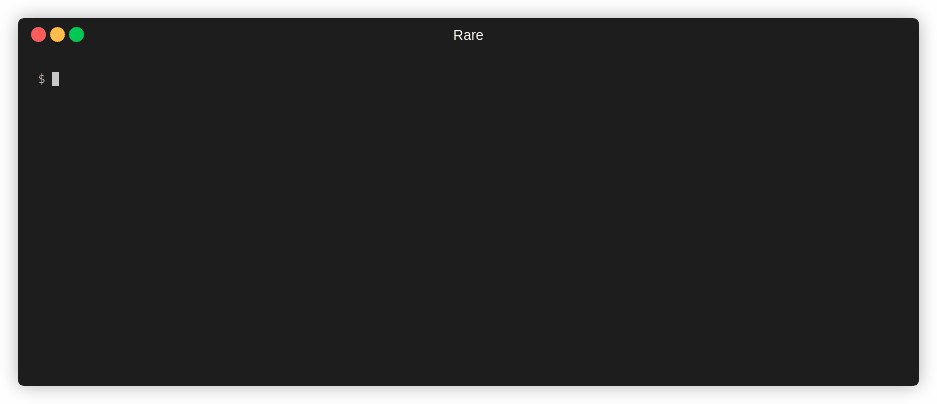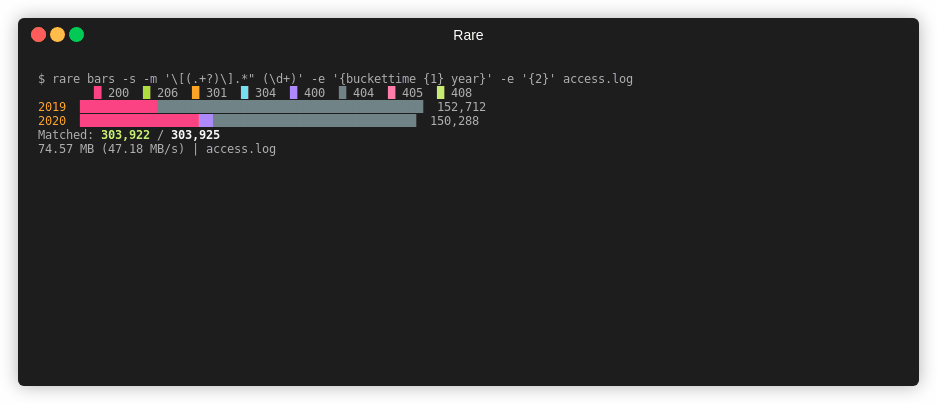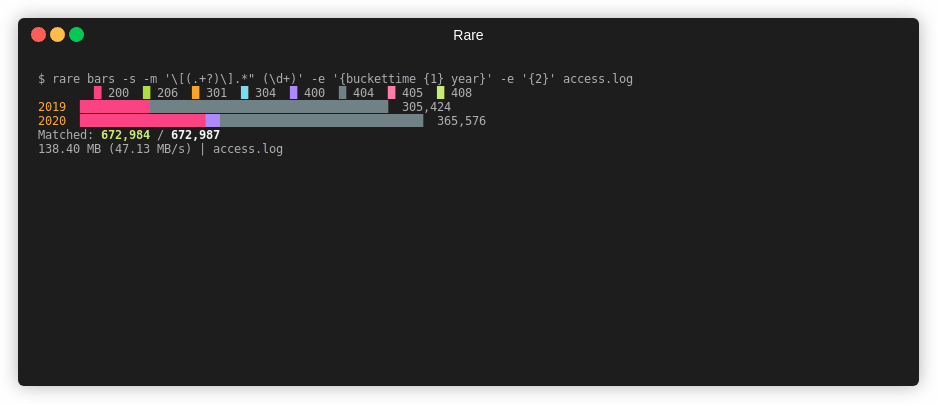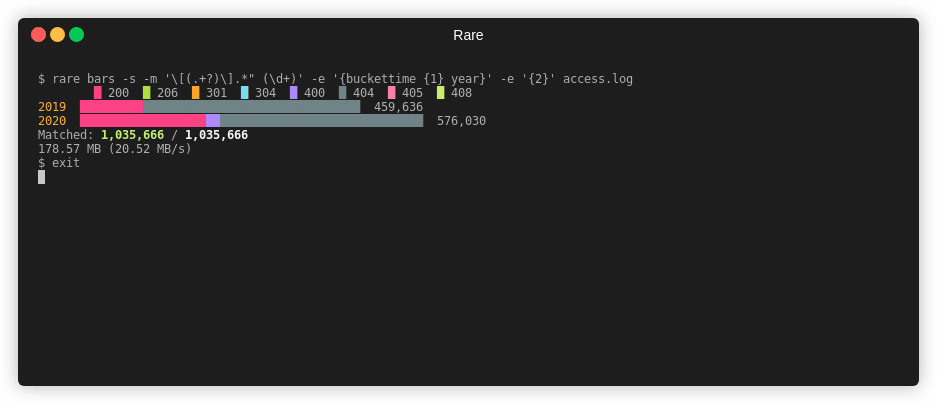
$ rare bars -sz -m "\[(.+?)\].*\" (\d+)" \
-e "{$ {buckettime {1} year nginx} {bucket {2} {multi 10 10}}}" \
testdata/*
0 200 1 300 2 400
2019 000000000222222222222222222222222222222 458,136
2020 0000000000000000002222222222222222222222222222222 576,030
Matched: 1,034,166 / 1,034,166
Numerical Analysis¶
rare help analyze
Summary¶
This command will extract a number from the match and run basic analysis on that number (Such as mean, median, mode, and quantiles).
Example¶
Note
-x or --extra will capture more information (Median, Mode, and Percentiles),
but dramatically slows down the analysis.
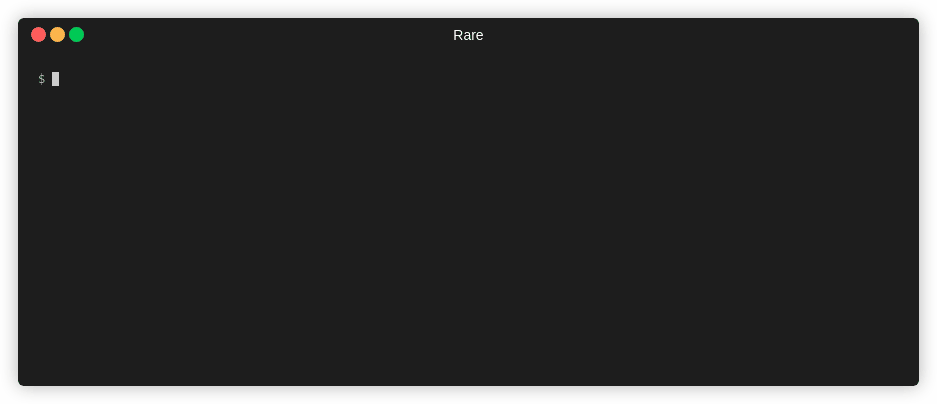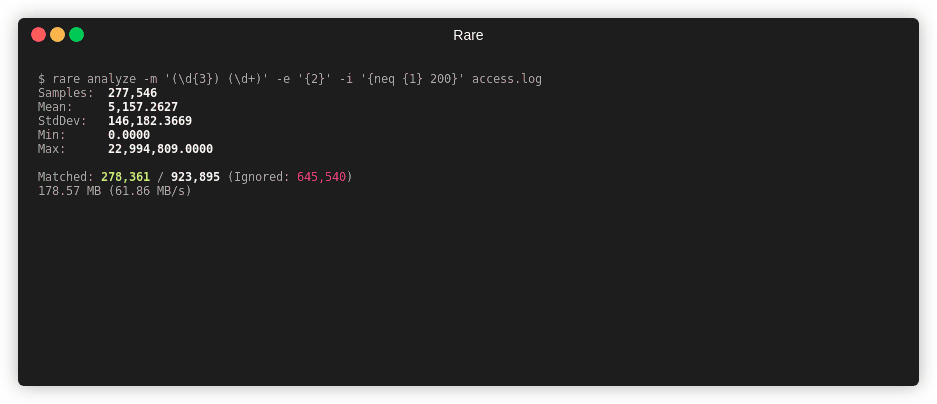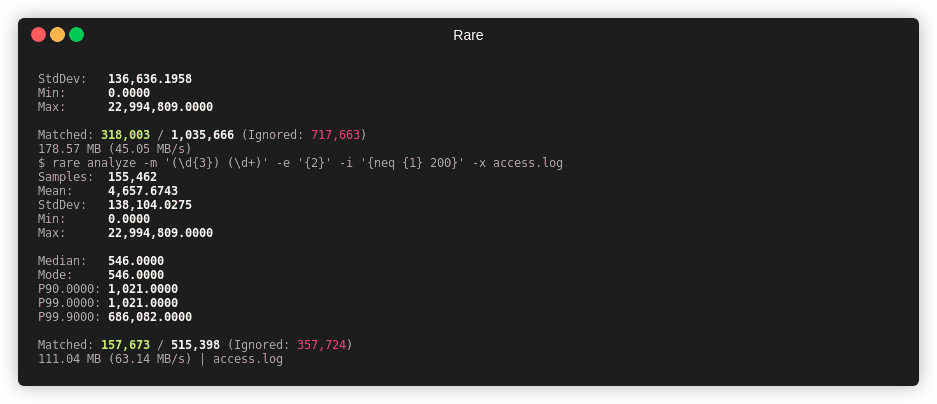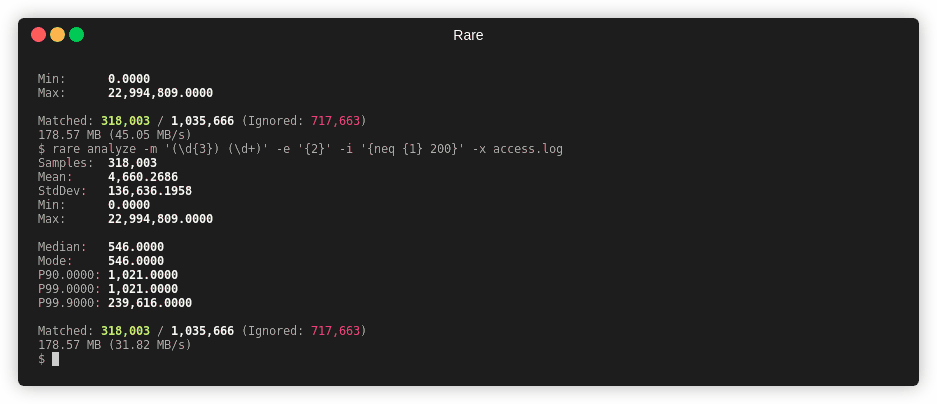
$ rare analyze --extra \
-m '"(\w{3,4}) ([A-Za-z0-9/.@_-]+).*" (\d{3}) (\d+)' \
-e "{4}" testdata/access.log
Samples: 161,622
Mean: 2,566,283.9616
Min: 0.0000
Max: 1,198,677,592.0000
Median: 1,021.0000
Mode: 1,021.0000
P90: 19,506.0000
P99: 64,757,808.0000
P99.9: 395,186,166.0000
Matched: 161,622 / 161,622
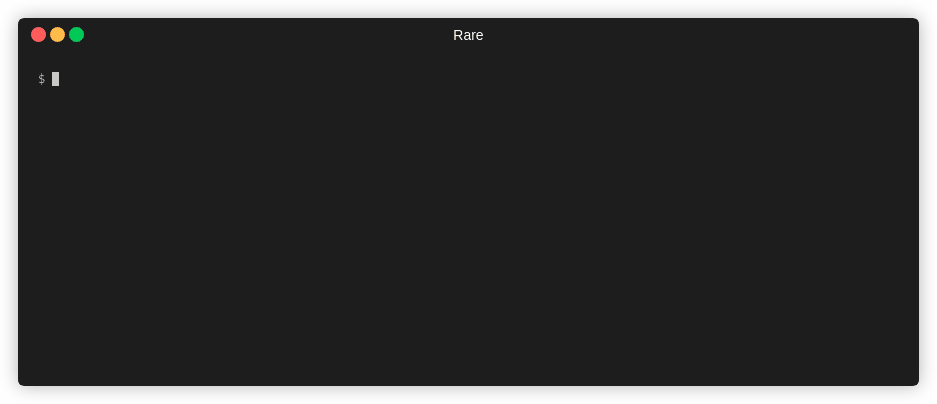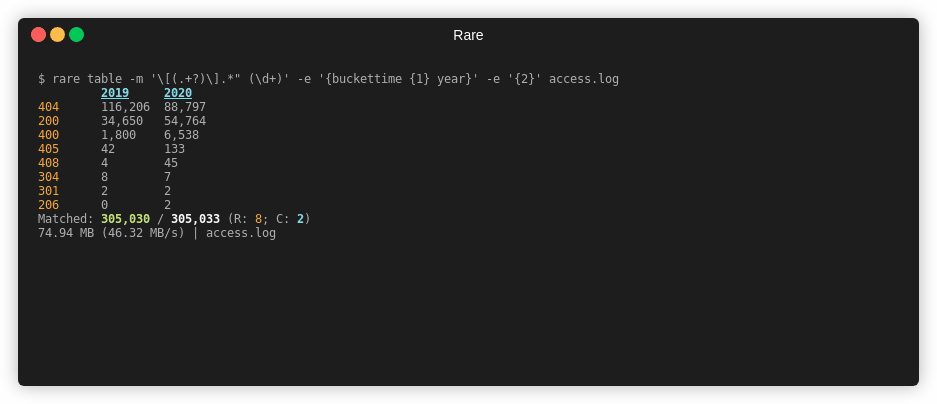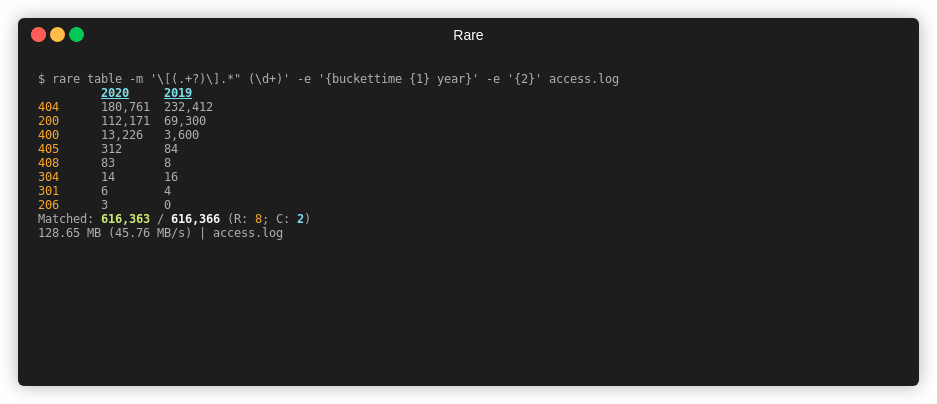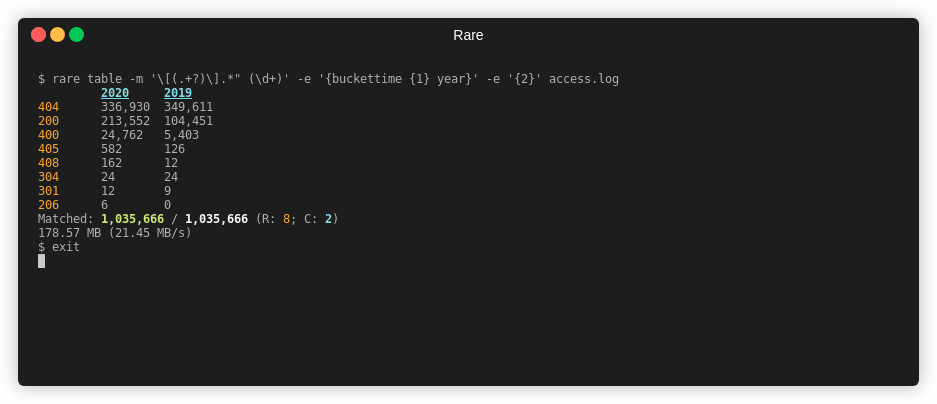
Table¶
rare help table
Summary¶
Create a 2D view (table) of data extracted from a file. Expression needs to
yield a two dimensions. Can either use \x00 or the {$ a b} helper. First
element is the column name, followed by the row name.
Example¶
$ rare tabulate -m "(\d{3}) (\d+)" \
-e "{$ {1} {bucket {2} 100000}}" -sk access.log
200 404 304 403 301 206
0 153,271 860 53 14 12 2
1000000 796 0 0 0 0 0
2000000 513 0 0 0 0 0
7000000 262 0 0 0 0 0
4000000 257 0 0 0 0 0
6000000 221 0 0 0 0 0
5000000 218 0 0 0 0 0
9000000 206 0 0 0 0 0
3000000 202 0 0 0 0 0
10000000 201 0 0 0 0 0
11000000 190 0 0 0 0 0
21000000 142 0 0 0 0 0
15000000 138 0 0 0 0 0
8000000 137 0 0 0 0 0
22000000 123 0 0 0 0 0
14000000 121 0 0 0 0 0
16000000 110 0 0 0 0 0
17000000 99 0 0 0 0 0
34000000 91 0 0 0 0 0
Matched: 161,622 / 161,622
Rows: 223; Cols: 6
Heatmap¶
rare help heatmap
Summary¶
Create a dense, color-coded, version of table-data by using cells to display
the strength of a value. Can either use \x00 or the {$ a b} helper. First
element is the column name, followed by the row name.
Supports alternative scales
Example¶
$ rare heatmap -m '\[(.+?)\].*" (\d+)' \
-e "{timeattr {time {1}} yearweek}" -e "{2}" access.log
- 0 5 22,602 9 45,204
2019-34..2019-41..2019-50..2020-15..2020-23..2020-31...2020-9
200 1111111111111111111111111111111111111111111111111111111-11111
206 -------------------------------------------------------------
301 -------------------------------------------------------------
304 -------------------------------------------------------------
400 -------------------------------------------------------------
404 33516265914153253212111-1511-13-141-1412-132111--14-1-1-13211
405 -------------------------------------------------------------
408 -------------------------------------------------------------
Matched: 1,035,666 / 1,035,666 (R: 8; C: 61)

Sparkline¶
rare help sparkline
Summary¶
Creates one or more sparklines based on table-style input. Provide
multiple inputs using {$ a b} helper. Unlike other output styles,
columns in the spark graph are right-aligned to always show
the most recent data on the right side.
Supports alternative scales
Example¶
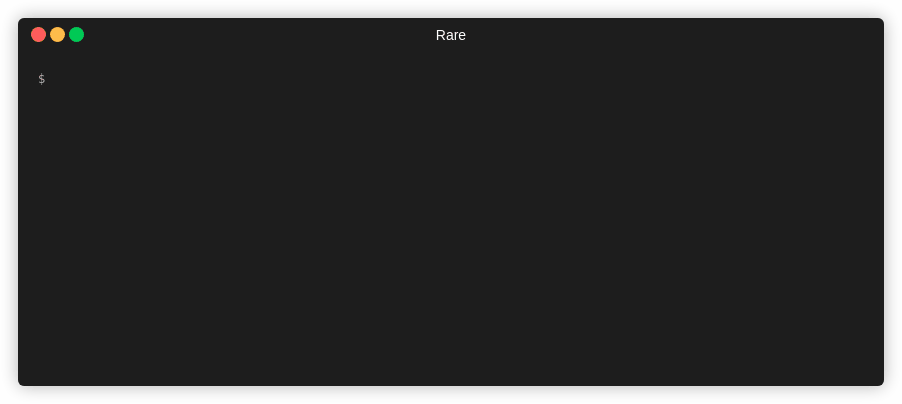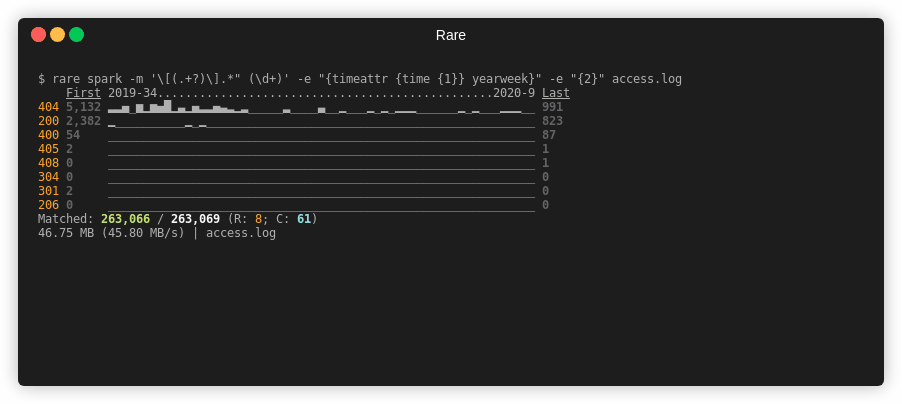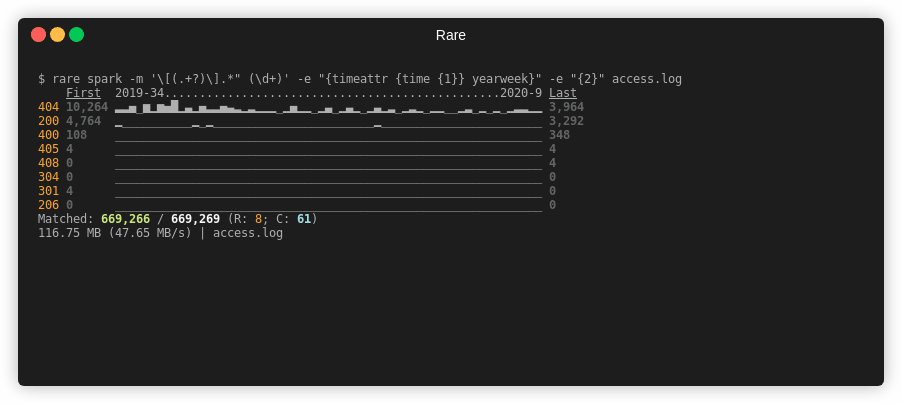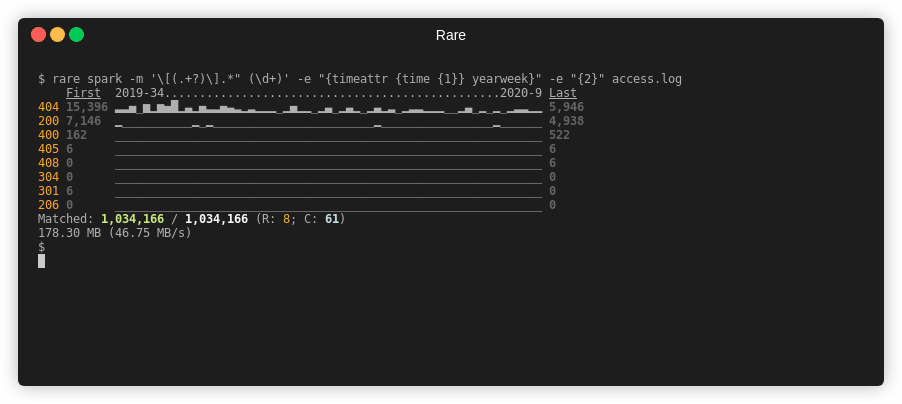
$ rare spark -m '\[(.+?)\].*" (\d+)' \
-e "{timeattr {time {1}} yearweek}" -e "{2}" access.log
First 2019-34................................................2020-9 Last
404 15,396 ..._._-.^_._.._..________.____.__.___.____________.______.___ 5,946
200 7,146 _____________________________________________________________ 4,938
400 162 _____________________________________________________________ 522
405 6 _____________________________________________________________ 6
408 0 _____________________________________________________________ 6
304 0 _____________________________________________________________ 0
301 6 _____________________________________________________________ 0
206 0 _____________________________________________________________ 0
Matched: 1,034,166 / 1,034,166 (R: 8; C: 61)
Reduce¶
rare help reduce
Summary¶
Create a set of values or table based on an expression that accumulates results. More powerful than table or histogram because it can interpret data in multiple ways in a single output. Also can group and sort results.
Usage:
- Extract data from a regex using
--match(-m) - Optionally group the data into buckets using
--group(-g). Can usekey=valueformat to give column a name - Specify one or more "accumulators", which are expressions.
{.}represents the current value, so for example,{sumi {.} {1}}adds the match{1}to the current value.- Can specify only expression,
key=expressionformat orkey:initial=expression. - Can reference past accumulators by key, eg
{divi {key1} {key2}}
- Can specify only expression,
- Optionally
--sortthe data based on an expression or reference to anaccumulator. eg.--sort {key1}. Can reverse with--sort-reverseflag
Example¶
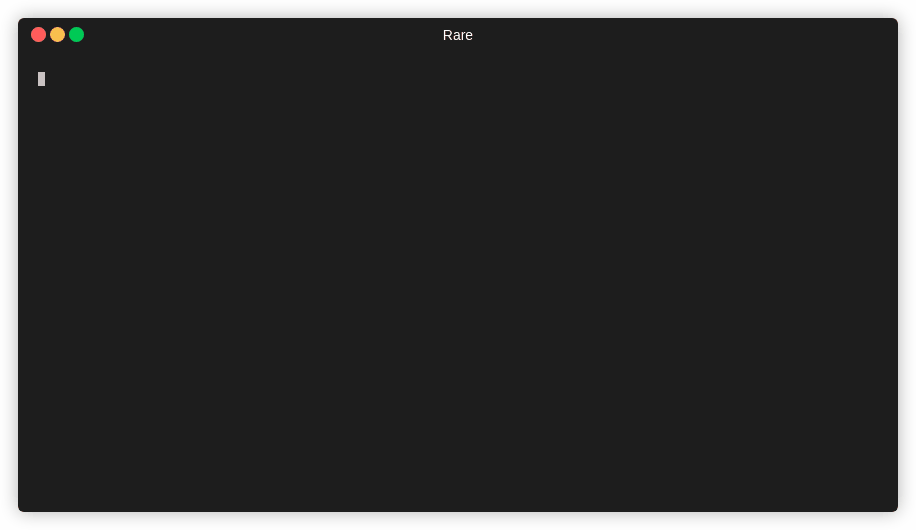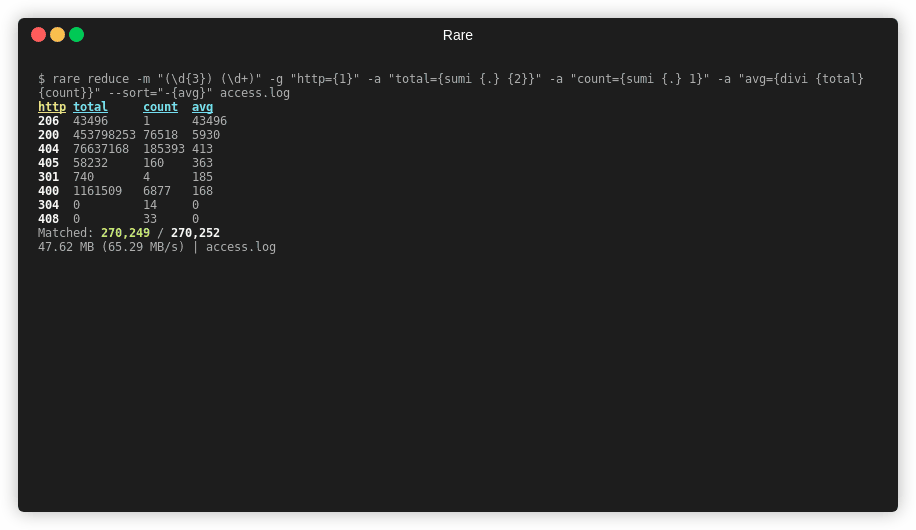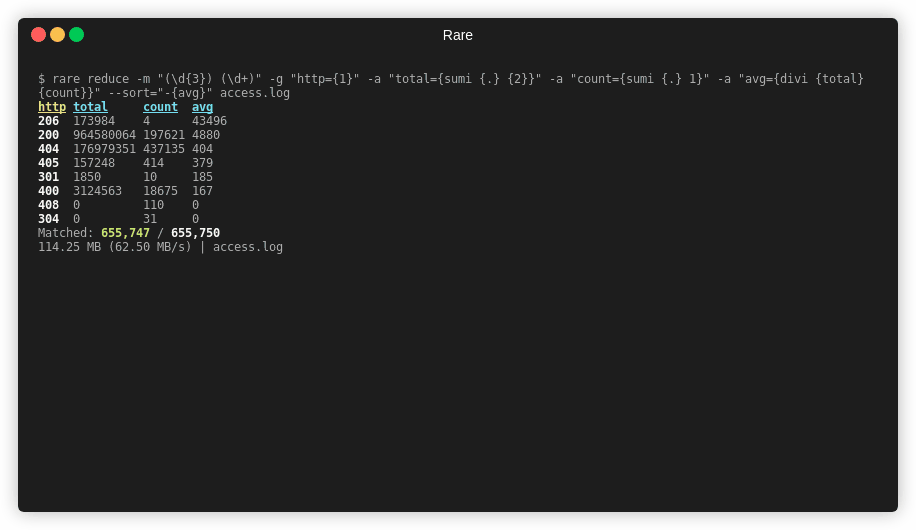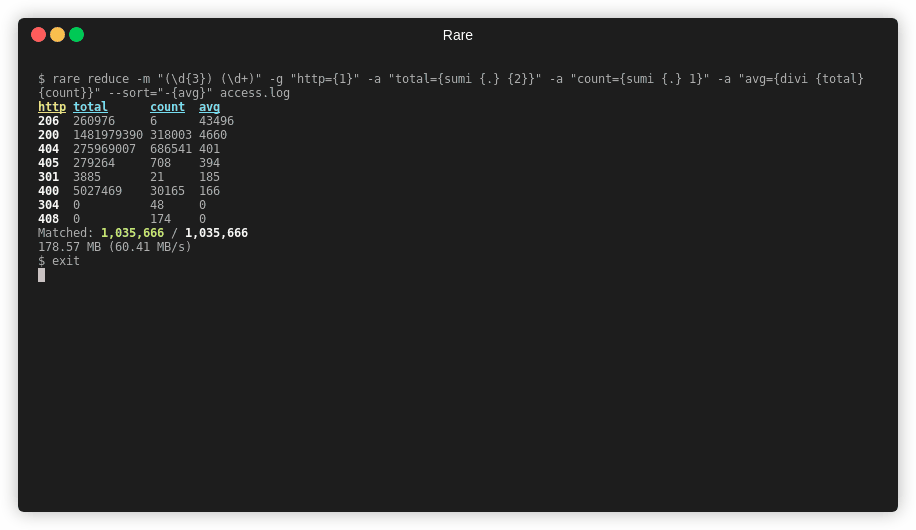
$ rare reduce -m "(\d{3}) (\d+)" -g "http={1}" -a "total={sumi {.} {2}}" \
-a "count={sumi {.} 1}" -a "avg={divi {total} {count}}" \
--sort="-{avg}" access.log
http total count avg
206 260976 6 43496
200 1481979390 318003 4660
404 275969007 686541 401
405 279264 708 394
301 3885 21 185
400 5027469 30165 166
304 0 48 0
408 0 174 0
Matched: 1,035,666 / 1,035,666
Common Arguments¶
Sorting¶
Many of the aggregators support changing the order in which the data is displayed in. You
can change this from default either by setting the --sort flag or --sort-rows and --sort-cols
flags for tables.
These are the supported sorters. You can shorthand to the first letter.
text-- Pure alphanumeric sort. Fastest, but can sort numbers oddly (eg. would sort 1, 11, 2, ...)numeric-- Attempts to parse the value as numeric. Falls back to alphanumericsmart-- Sorts by the first found number in the string. Falls back to alphanumeric (default)contextual-- Tries to use context to be smart about sorting, eg if it sees a month or weekday name, will sort by that. Falls back to numericdate-- Parses the value as if it were a date. Falls back to contextualvalue-- Orders the results based on their aggregated value. eg. would put the most frequent item at the top. Defaults to descending order
Modifiers¶
In addition to the sorting method, you can also modify the sort by adding a colon and the modifier, eg: numeric:desc
These are the supported modifiers. You can shorthand to the first letter.
:reverse-- Reverse of the "default":asc-- Ascending order:desc-- Descending order
Alternative Scales¶
Some of the aggregators support alternative display scaling: linear (default), log10, and log2.
In aggregators that support it, you can specify with --scale log10
Formatting¶
Many of the aggregators support custom number formatters, defaulting to simply humanize it (add commas).
You can specify a custom expression to format the output via --format.
Alternatively, you can short-hand the function name when it's a simple formatter (that only accepts 1 argument).
It has 3 arguments:
{0}or{value}-- Value being formatted{1}or{min}-- The min value in the set{2}or{max}-- The max value in the set
eg.
{bytesize {value}}ORbytesize-- Convert the number to bytes{downscale {0}}ORdownscale-- Convert to suffixed-numbers (k, M, etc){percent {0} 2 {1} {2}}-- Converts the value to a percentage based on the range from min to max
CSV Output¶
Many of the aggregators support outputting the final results to csv. You can do this
with --csv <filename>.
Additionally, you can output to stdout with -, which causes nothing else to be
output.
Example:
rare histo --match "(\d+)" -e "{1}" --csv - simple.log