rare¶


![]()


A fast text scanner/regex extractor and realtime summarizer. Quickly search, reformat and visualize text files such as logs, csv, json, etc.
Supports various CLI-based graphing and metric formats (filter (grep-like), histogram, table, bargraph, heatmap, reduce).
rare is a play on "more" and "less", but can also stand for "realtime aggregated regular expressions".
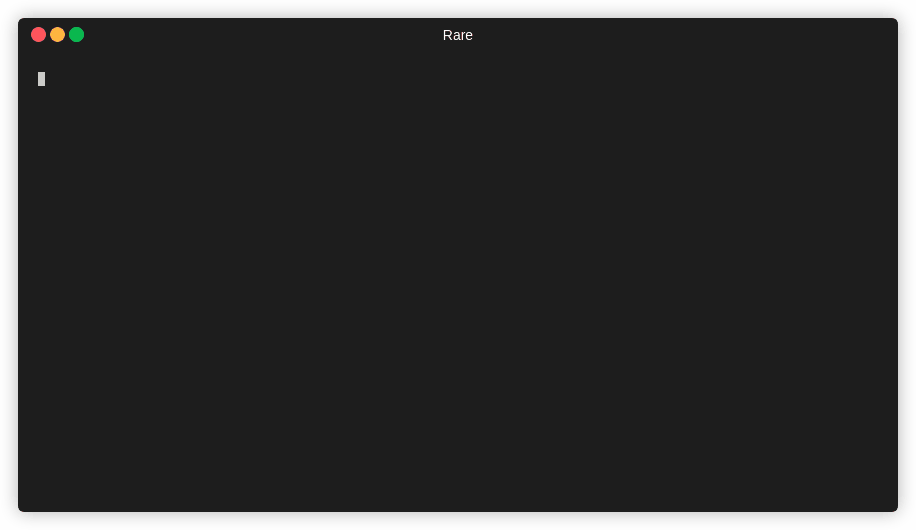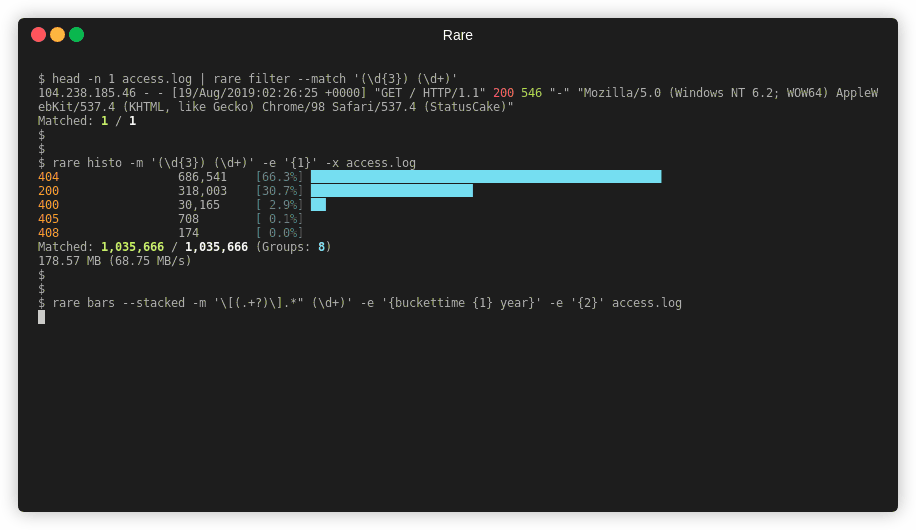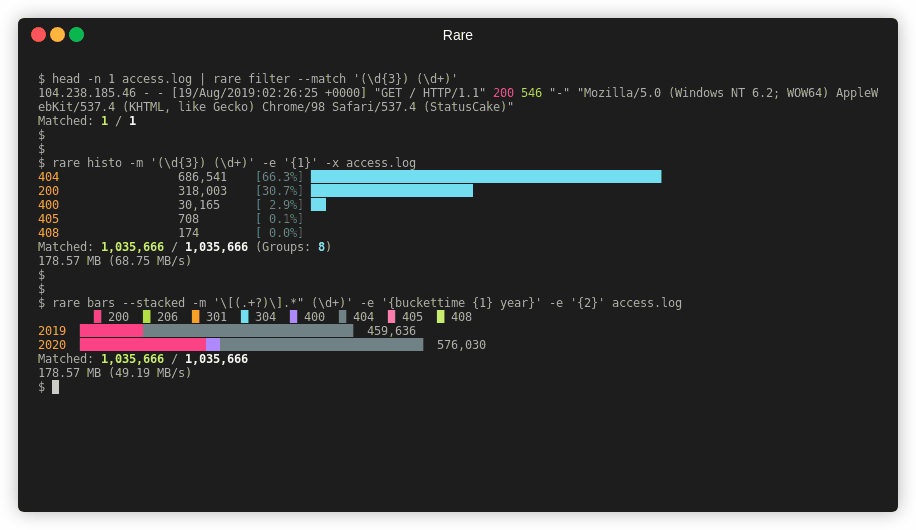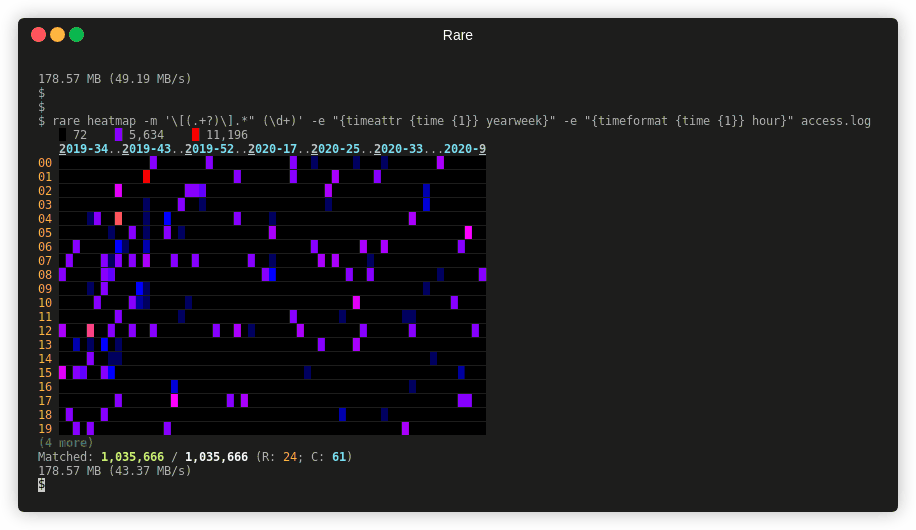
Features¶
- Multiple summary formats including: filter (like grep), histogram, bar graphs, tables, heatmaps, sparklines, reduce, and numerical analysis
- Parse using regex (
-m) or dissect tokenizer (-d) - Manipulate results with handlebars-like expressions (
-e) - File glob expansions (eg
/var/log/*or/var/log/*/*.log) and recursion-Rwith path filters (include/exclude patterns) - Optional gzip decompression (with
-z) - Following
-for re-open following-F(use--pollto poll, and--tailto tail) - Ignoring lines that match an expression (with
-i) - Aggregating and realtime summary (Don't have to wait for all data to be scanned)
- Multi-threaded reading, parsing, and aggregation (It's fast)
- Color-coded outputs (optionally)
- Pipe support (stdin for reading, stdout will disable realtime, and
--csvformatting) eg.tail -f | rare ... > out
Take a look at examples to see more of what rare does.
Installation¶
A Note on PCRE (Perl Compatible Regular Expressions)
Besides your standard OS versions, there is an additional pcre build which is ~4x faster than go's re2 implementation in moderately complex cases. In order to use this, you must make sure that libpcre2 is installed (eg apt install libpcre2-8-0 or dnf install pcre2). Right now, it is only bundled with the linux distribution.
PCRE2 also comes with pitfalls, two of the most important are:
1. That rare is now dynamically linked, meaning that you need to have libc and libpcre installed
2. That pcre is an exponential-time algorithm (re2 is linear). While it can be significantly faster than go's re2, it can also be catastrophically slower in some situations. There is a good post here that talks about regexp timings.
I will leave it up to the user as to which they find suitable to use for their situation. Generally, if you know what rare is getting as an input, the pcre version is perfectly safe and can be much faster.
Bash Script¶
Warning: Verify Script
As a best practice, you should always verify any script before piping to bash.
This script downloads the latest version from github, and installs it to ~/.local/bin (/usr/bin if root).
curl -sfL https://rare.zdyn.net/install.sh | bash
Manual (Prebuilt Binary)¶
Download appropriate binary or package from Releases
Homebrew¶
brew tap zix99/rare
brew install rare
Community Contributed¶
Note
The below install methods have been contributed by the community, and aren't maintained directly.
MacPorts¶
sudo port selfupdate
sudo port install rare
From code¶
Clone the repo, and:
Requires GO 1.23 or higher
go mod download
# Build binary
go build .
# OR, with experimental features
go build -tags experimental .
Available tags:
experimentalEnable experimental features (eg. fuzzy search)pcre2Enables PCRE 2 (v10) where able. Currently linux onlyrare_no_pprofDisables profiling capabilities, which reduces binary sizeurfave_cli_no_docsDisables man and markdown documentation generation, which reduces binary size
Quickstart¶
The easiest way to start using rare is by creating a histogram.
Each execution is usually composed of two parts, the regex extracted match (-m) and the expression (-e).
$ rare histo \
-m '"(\w{3,4}) ([A-Za-z0-9/.]+).*" (\d{3})' \ # The regex that extracts match-groups
-e '{3} {1}' \ # The expression will be the key, referencing the match-groups
access.log # One or more files (or -R for recursion)
200 GET 160663
404 GET 857
304 GET 53
200 HEAD 18
403 GET 14
Next¶
To learn more, check out the aggregators, read some examples or dig into the overview.